ストレス科学を職場研修に変える研究ノート
ストレス研究の統計用語|論文理解に必要な基礎知識
この記事では、ストレス研究や職場ストレスに関する論文を読むときに出てくる統計用語を整理します。統計用語をすべて専門家のように使いこなす必要はありません。ただ、研究結果を読むときに「何を測っているのか」「どこまで言える結果なのか」を見誤らないためには、基本的な言葉の意味を押さえておくことが大切です。人事総務・健康経営担当者が、研修や職場改善の根拠として研究を読む際にも役立つ内容です。
ストレス研究で統計用語が必要になる理由
ストレス研究では、気分、疲労感、バーンアウト、職場満足度、睡眠、心拍数変動など、目に見えにくい状態を測定します。そのため、質問紙や尺度、統計モデルを使って、心身の状態をできるだけ客観的に捉えようとします。
たとえば、「ストレスが高い」と一言で言っても、その中には疲労感、不安、怒り、身体症状、仕事への意欲低下など、複数の要素が含まれます。研究では、それらを分けて測るために、因子分析、リッカート尺度、項目反応理論などが使われます。
統計用語を理解しておくと、論文の結果をそのまま鵜呑みにせず、「この研究では何を測ったのか」「どの範囲まで職場に応用できるのか」を落ち着いて読めるようになります。
探索的因子分析とは
探索的因子分析とは、複数の質問項目の背後に、どのようなまとまりがあるのかを探る方法です。英語では exploratory factor analysis と呼ばれ、EFA と略されます。
たとえば、ストレスに関する質問紙に「疲れやすい」「眠れない」「集中できない」「人と話すのがつらい」などの項目があるとします。これらの回答を分析すると、身体的疲労、心理的負担、対人ストレスなど、いくつかのまとまりが見えてくる場合があります。
探索的因子分析は、あらかじめ強い仮説を決めすぎず、データの中にどのような構造があるのかを確認したいときに使われます。
確認的因子分析とは
確認的因子分析とは、研究者があらかじめ考えた因子構造が、実際のデータに合っているかを確かめる方法です。英語では confirmatory factor analysis と呼ばれ、CFA と略されます。
探索的因子分析が「どのようなまとまりがあるのかを探る方法」だとすれば、確認的因子分析は「このまとまり方で本当に合っているのかを確かめる方法」です。
たとえば、あるストレス尺度が「情緒的疲労」「脱人格化」「個人的達成感の低下」という3つの要素で成り立つと考えられている場合、その3つの構造が実際の回答データに合っているかを確認します。
因子負荷量とは
因子負荷量とは、ある質問項目が、特定の因子とどのくらい強く関係しているかを示す数値です。
たとえば、「朝から疲れている」という項目が、身体的疲労という因子と強く関係していれば、因子負荷量は大きくなります。反対に、その項目が因子とあまり関係していなければ、因子負荷量は小さくなります。
ストレス尺度を読むときは、因子負荷量を見ることで、その質問項目が本当に測りたい内容に合っているかを確認できます。
一次元性とは
一次元性とは、複数の質問項目が一つの同じ性質を測っていると考えられる状態です。
たとえば、ある下位尺度が「疲労感」を測るものなら、その中の項目はできるだけ同じ方向の疲労感を捉えている必要があります。項目ごとにまったく違う内容を測っていると、その下位尺度の意味がぼやけます。
論文で「一定の一次元性が満たされている」と書かれている場合、その下位尺度は一つのまとまりとして扱える可能性がある、という意味で読みます。
リッカート尺度とは
リッカート尺度とは、「まったく当てはまらない」から「非常によく当てはまる」までのように、段階を選んで答える質問形式です。
職場ストレスの質問紙でも、リッカート尺度はよく使われます。たとえば、「仕事のあとに疲れが残る」という質問に対して、1から5までの段階で答える形式です。
はい・いいえの二択よりも、感じ方の強さを細かく捉えられるため、ストレス、満足度、不安、疲労感、職場の支援感などを測るときに使われます。
分散とは
分散とは、データがどのくらい散らばっているかを示す数値です。
たとえば、社員アンケートで全員がほぼ同じ回答をしていれば、分散は小さくなります。反対に、回答が大きく分かれていれば、分散は大きくなります。
職場のストレス調査では、平均値だけを見ると見落とすことがあります。平均はそれほど高くなくても、一部の部署や一部の社員だけ強い負担を感じている場合があるからです。分散を見ることで、回答のばらつきに気づきやすくなります。
標準偏差とは
標準偏差とは、データが平均値からどのくらい離れているかを示す基本的な数値です。分散の平方根として計算されます。
標準偏差が小さい場合、回答は平均の近くに集まっています。標準偏差が大きい場合、回答にばらつきがあります。
人事総務・健康経営担当者が調査結果を見るときは、平均値だけでなく標準偏差も見ると、職場内の差に気づきやすくなります。
項目反応理論とは
項目反応理論とは、質問項目への回答から、回答者の特性をより詳しく推定するための考え方です。英語では Item Response Theory と呼ばれ、IRT と略されます。
従来の合計点だけを見る方法では、同じ点数でも、どの項目にどう答えたのかまでは十分に見えません。項目反応理論では、それぞれの項目がどの程度その人の特性を反映しているのかを考えます。
ストレス研究では、尺度の質問項目がどれだけ適切に対象者の状態を捉えているかを確認する際に使われることがあります。
段階反応モデルとは
段階反応モデルとは、項目反応理論の一つです。リッカート尺度のように、複数の段階で答える質問に使われます。
たとえば、「まったく当てはまらない」「あまり当てはまらない」「少し当てはまる」「よく当てはまる」のような回答では、単純な正解・不正解ではありません。段階反応モデルでは、このような段階的な回答を使って、回答者の状態を推定します。
ストレスや疲労感の調査では、回答が段階で示されることが多いため、段階反応モデルは心理尺度の研究で重要な考え方になります。
2パラメタ・ロジスティックモデルとは
2パラメタ・ロジスティックモデルとは、項目反応理論で使われるモデルの一つです。主に、項目の識別力と困難度を使って、回答の確率を表します。
識別力とは、その項目が回答者の違いをどのくらいよく見分けられるかを示すものです。困難度とは、その項目に該当しやすいかどうかの位置を示すものです。
教育テストでは正答確率を考えるときに使われますが、心理尺度では、ある項目にどの程度反応しやすいかを考える際に応用されます。
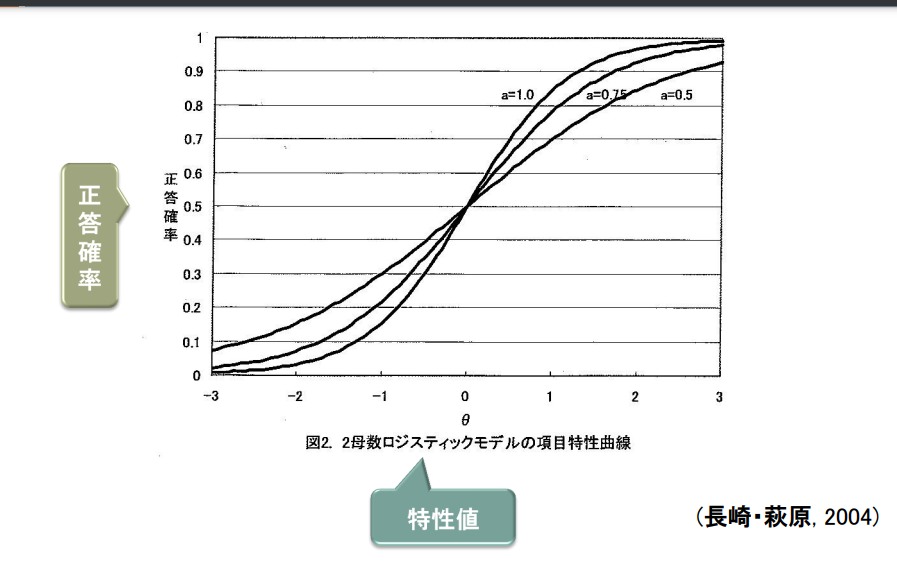
2パラメタ・ロジスティックモデルの説明図
識別力・困難度・当て推量とは
ロジスティックモデルでは、項目の性質を表すために、いくつかのパラメータが使われます。
- 識別力:回答者の特性の違いを、その項目がどのくらい反映できるかを示します。
- 困難度:その項目がどの程度反応されやすいか、または難しいかを示します。
- 当て推量:偶然に正答する可能性を考えるときに使われます。
ストレス研究で心理尺度を読む場合は、これらの言葉が出てきたら、「項目の質や働きを見ている」と捉えると読みやすくなります。
累積確率曲線とは
累積確率曲線とは、ある値以下になる確率を積み上げて表す考え方です。
たとえば、さいころを投げたときに「4以下の目が出る確率」を考える場合、1、2、3、4が出る確率を合わせて見ます。このように、ある範囲までの確率を積み上げて考えるときに、累積確率という言葉が使われます。
心理尺度や項目反応理論では、回答者がある選択肢以上を選ぶ確率を考えるときなどに、累積確率の考え方が使われます。
多変量正規分布とは
多変量正規分布とは、正規分布を複数の変数に広げた考え方です。
ひとつの変数だけを見るのではなく、複数の変数がどのように関係しているかを扱います。たとえば、疲労感、不安、睡眠の質、仕事量などを同時に見る場合、複数の変数の関係を考える必要があります。
統計モデルでは、データがどのような分布をしているかを前提として分析することがあります。そのため、論文の方法部分で多変量正規分布という言葉が出ることがあります。
mirtパッケージとは
mirtパッケージとは、統計ソフトRで項目反応理論を扱うためのパッケージです。多次元の項目反応モデルを使う研究で利用されます。
ストレス尺度やバーンアウト尺度の研究では、複数の下位尺度を同時に扱うことがあります。そのような場合、mirtのようなパッケージを使って分析することがあります。
読者として論文を読む場合は、mirtという名前を見たら、「項目反応理論を使った分析に用いられたRの道具」と理解しておけば十分です。
lavaanパッケージとは
lavaanパッケージとは、統計ソフトRで構造方程式モデリングや確認的因子分析などを行うためのパッケージです。
ストレス研究では、複数の要因がどのように関係しているかを調べることがあります。たとえば、仕事量、上司の支援、疲労感、離職意向などの関係を見るときです。
lavaanという言葉が出てきた場合は、「仮説モデルとデータの合い方を見るための分析に使われた」と読むと理解しやすくなります。
多母集団の同時分析とは
多母集団の同時分析とは、複数のグループを同時に比較しながら分析する方法です。
たとえば、教員と看護職、管理職と一般社員、男性と女性、若年層と中堅層など、複数のグループで同じ尺度が同じように使えるかを確認したいときに用いられます。
職場ストレスの研究では、同じ質問紙でも職種や立場によって受け止め方が違う可能性があります。多母集団の同時分析は、その違いを確認するために使われます。
企業研修で統計用語をどう扱うか
タニカワ久美子の企業研修では、統計用語を参加者に覚えさせることを目的にしていません。大切なのは、調査結果や研究データを見たときに、数字だけで社員を判断しない視点を持つことです。
たとえば、ストレスチェックの平均値だけを見ると、「全体としては問題が少ない」と感じることがあります。しかし、回答のばらつきが大きい場合、一部の部署や特定の職種に強い負担が集中している可能性があります。
研修の現場では、人事総務・管理職の方から「数値を見ると安心してしまうが、現場の感覚とは違うことがある」と相談されることがあります。そのときは、平均だけでなく、ばらつき、自由記述、面談での声、欠勤や離職の動きまで合わせて見ることを伝えています。
統計用語は、難しい言葉を並べるためのものではありません。社員の不調を早めに拾い、職場の負担を見落とさないために、数字の読み方を支える道具として扱うことが大切です。
統計用語は研究を職場に活かすための土台になる
ストレス研究の統計用語は、一見すると難しく感じます。しかし、用語の意味を少し知っておくだけで、論文の読み方は変わります。
探索的因子分析は、質問項目のまとまりを探る方法です。確認的因子分析は、仮説どおりの構造になっているかを確かめる方法です。リッカート尺度は、感じ方の強さを段階で答える方法です。項目反応理論は、項目ごとの働きを詳しく見る考え方です。
人事総務・健康経営担当者が研究を読むときは、すべての計算方法を覚える必要はありません。どのような調査で、何を測り、どこまで職場に使える結果なのかを見ることが重要です。
ストレス研究や調査結果を職場の不調予防に活かしたい場合は、ストレスマネジメント研修をご確認ください。
参考文献
- 芝祐順 編『項目反応理論―基礎と応用―』東京大学出版会,1991年
- 長崎栄三・萩原康仁『算数達成度の項目反応理論による比較分析』国立教育政策研究所,2004年
- 服部環『心理・教育のためのRによるデータ解析』福村出版,2011年
- 村木英治『項目反応理論』朝倉書店,2011年
研修テーマが未定でも、対象者・職場状況・実施時期に合わせて整理します。
